
This past weekend, I played in TJCTF with les amateurs. We ended up in 1st place!
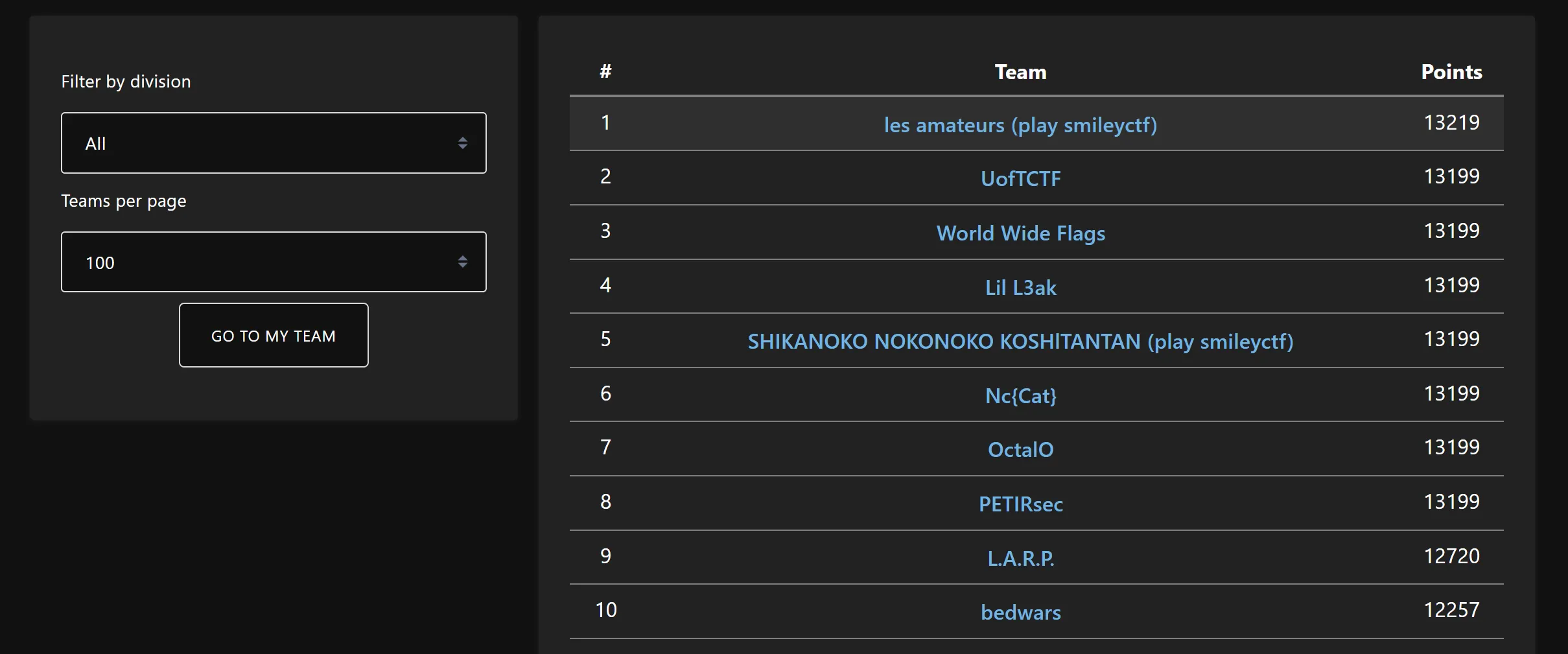
We won because we were the only team to solve misc/golf-hardester. In this write-up, I will be
documenting my thought process while solving golf-hardester.
Challenge Breakdown
golf-hardester is a regex golfing challenge where you are given sample texts to match and sample
texts to not match, and you must write a regex within a certain character limit that matches the pattern.
There are 5 levels, each of which has its own pattern that you must write a regex for. To get the flag,
you must solve all 5 levels.
In this write-up, I will mainly be focusing on level 5, as it was by far the most difficult and was the one where most teams got stuck on.
Levels 1-4
Level 1
1. "Warmup" This one's pretty straightforward.
Match on all of these: But none of these:------------------------ ------------------------ampasimenite jasmoneanchorable decisivenessesaconic backoffantistrophic whitebarkabrade physogastrismarroya shaveeapoplex hanoverianayahs weatherstrippedarock naturalizeanconoid lophotrichousanglophile nonprecedentialacalephan tjctfamaze shepherdiaadelphe waymarkanno picnickeramiable bottleholderaliquid poruleachromatin diagramingaircheck solifugeantigenically phrenetically
Maximum allowable length is 2The pattern is just to match any string that begins with an a.
^aLevel 2
2. "Tenet" It's a classic chicken-and-egg question: Which came first, the Roman graffiti or the Christopher Nolan movie?
Match on all of these: But none of these:------------------------- ---------------------------------------------satorarepotenetoperarotas chirldecaleminacivicanimelaced kayakstrawtrelareferalertwarts croisstrutannotdaweshakamanasakayakasanamakah khnabadalanamanaladabanhkdimitinarimadamiranitimid parssalertrevertrelassrapfaradaromarotoramoradaraf makahadelykerekyledahakambanakaholanoyonalohakanab crimpgruftgowermairsjessilassoartusstetssutraossal nasabbnamasamasamanbbasanrakisanolikodokilonasikar mfssaartusstatssutraassfmtadesaneledewedelenasedat camusvmelumesemulemvsumacassetscamesalasemacstessa tknakaronanoyonanorakanktcestiecartsamastraceitsec sejabenemarexeramenebajesgnatsnonetananatenonstang esshmshamasamasamahsmhsserotasoperatevetareposator talasaladalwvwladalasalatrakesamenekeyekenemasekar talasadelslemelsledasalatsalemanelelemelelenamelas areposatortenetrotasoperaassesspalesamaselapssessa faradaledaaeveaadeladarafdartsavertrevertrevastrad assamshampsalaspmahsmassacoramoletareveratelomaroc nesoaevilssirissliveaosennertaecartradartraceatren zaiananasamadamasananaiazharamadelareferaledamarah kayakkayakkayakkayakkayaklatonanimotipitominanotal kanltadalanamanaladatlnakkedarenemadewedameneradek batheskaldifritfacksladesremopmasseattisstatssittaessam awhetmeresfatalabdulaboonamulagiamokelsielapslavalspaleislek ervumkemmemuzakalgiaapersdikesswinkrizzowaresalonerotorenolaseraw avenspairtstrohaddiasixthaeriesclavtepeecribssusanulemasexesamelunasus
Maximum allowable length is 50The pattern here is a bit difficult to see, but the rule is to match any string that matches the following conditions:
- The string must be a palindrome.
- The string must be 25 characters long.
- The 2nd character must be the same as the 6th character.
- The 3rd character must be the same as the 11th character.
- The 4th character must be the same as the 10th character.
- The 7th character must be the same as the 12th character.
To match a palindrome, we can use the regex module’s
recursion feature.
This regex matches any palindrome:
^(.|(.)(?1)\2)$Here, we have a base case of a single character. In the recursive case, we capture a character, recursively match the regex, then backreference the captured character to ensure it occurs again at the end of the string.
We can match conditions 2-6 with the following regex:
^.(.)(.)(.).\1.(.).\3\2\4.{13}$We can then combine the two regexes using a lookahead:
^(?=(.|(.)(?1)\2)$).(.)(.)(.).\3.(.).\5\4\6.{13}$Level 3
3. "Triumvirate" Ah yes, quinary, my fifth favorite base.
Match on all of these: But none of these:----------------------------------- ----------------------------------0 13 411 21014 1131022 21413124430 32130020302402301 3030320142122423144312 231332302134111413130043 1102200310204303402023233320 1422343112104210130424322431012 11031030411213204331243200410022310 1002104210220442101420210414114303030 1114412243313242103302100312023023123 244403142003144230442020212213114432333240 104310214210310332001243332123330120041301 431140423202034404111403212440313014044442 112210314002204031222432301404334330404131321 20113122400131413033301413011141021024302200400 1140420131230132311231023444210332323242404120224132 102310311320124044204140131114401022024420003234234444 100044123310122023041400411233313020411424304401310144130040302 1021231134414114301242044323030111202241201424204222113011221133 20121332123142340324001223212344234343341022001132401403022101104 42441333222430014043301433413001231421441204321403132040024202002 24231010323432410001133113023033410410400231012014340122214134013042 1441413341001141224132000024031214
Maximum allowable length is 70The pattern here is to match any base-5 number that is divisible by 3.
The idea here is that we will step through each digit, and keep a running count of the number modulo 3.
Once we reach the end of the string, our running count will be the entire number, modulo 3. Thus, we can
match only strings that end with a running count of 0 (mod 3). For example, consider the base-5 number 124
(39 in decimal). This is how our regex will evaluate it:
count starts at 0[1]23 -> count = (count * 5) + 1 = (0 * 5) + 1 = 1 (mod 3)1[2]3 -> count = (count * 5) + 2 = (1 * 5) + 2 = 1 (mod 3)12[4] -> count = (count * 5) + 4 = (1 * 5) + 4 = 0 (mod 3)string ends with count = 0, so we accept itThe trick here is that, because we are operating mod 3, the count variable can only have 3 values: 0, 1,
or 2. We can create three separate regexes to model each possible value of count:
count_0: $|[03](?&count_0)|[14](?&count_1)|2(?&count_2)count_1: [03](?&count_2)|[14](?&count_0)|2(?&count_1)count_2: [03](?&count_1)|[14](?&count_2)|2(?&count_0)Combining these three regexes, and stripping group names to make it shorter, we get:
^($|[03](?1)|[14]([03]([03](?2)|[14](?3)|2(?1))|[14](?1)|2(?2))|2(?3))Level 4
4. "Lucky Number" I don't think you need any hints as to which base this is.
Match on all of these: But none of these:------------------------ ------------------------0 1111 101110 1110101 10011100 101100011 110101010 1000110001 1001111000 1010111111 10111000110 11001001101 11011010100 11111011011 100001100010 100011101001 100101110000 100111110111 101001111110 1011010000101 1011110001100 10110110010011 110000110011010 110111110100001 1011101110101000 1111010010101111 1111011110110110 10011011010111101 10000111111000100 11000101011001011 11111000011010010 10110100111011001 11011111011100000 101110001111100111 101001011111101110 111000000111110101 101101101111111100 1001101110100000011 1011110110100001010 1001100110100010001 1010001111
Maximum allowable length is 162The pattern here is to match any base-2 number that is divisible by 7.
We can use the same technique as in level 3.
^(?<s0>$|0(?&s0)|1(?<s1>0(?<s2>0(?<s4>0(?&s1)|1(?&s2))|1(?<s5>0(?&s3)|1(?&s4)))|1(?<s3>0(?<s6>0(?&s5)|1(?&s6))|1(?&s0))))Level 5
5. "Tally" Alright, time for a real challenge. This one should actually be difficult!
Match on all of these: But none of these:------------------------ ------------------------arraigning edifiednonordered unreverberatingabadbacdcacbdbdc underpassmesosome interinsertananna pilferedunendued nippinesstromometer gregariniancaucasus deicideintestines nonaristocratici rototillerdeed ozonizinghorseshoer museumshappenchance backbreakerreappear interradiateddeeded antistallingpullup naturalizearraigning equitriangulartestes reparticipatemononymy ppdscintillescent miasmascouscous cabbage
Maximum allowable length is 62Now, we get to the last level, and the hardest one by far.
Luckily, by the time that I had gotten to this level, the author had already released a hint about what the
pattern to match is:

We need to match any string that has equal number of occurrences of all the unique characters in the string.
Brainstorming
One of the first things that my teammate and I noticed was that because of the transitive property of equality, we only actually need to check that a given character has the same number of occurrences as only one other character in the string. We do not need to test every character against every other character.
For example, in the string aabbcc:
- Checking
aagainstb, they both have 2 occurrences. - Checking
bagainstc, they both have 2 occurrences. - We automatically know that
aandchave the same number of occurrences by the transitive property of equality.
This insight allows us to come up with an algorithm that may be possible to implement in regex that satisfies the pattern:
- Step through each character in the string.
- Check if the current character and the character that follows it have the same number of occurrences.
- If all characters pass this test, then the string is valid.
Now that we had an idea for an algorithm, I started implementing it in regex. My goal was to first implement a regex that passes the test cases, then to golf it down to fit into the 62 character limit.
Matching Equal Counts (part 1)
Starting simply, I first wanted to make a regex that matched any string that had equal counts of the characters a and b,
assuming the string had no other characters other than as and bs.
The key insight that I had here is: if there are equal counts of as and bs, then we can pair up every single a with a
single b. Thus, if the first character is an a, then there must be a b somewhere later in the string that we can pair
the a up with (and vice versa).
In regex, that would look something like this:
^(a.*b|b.*a)It is possible for there to be multiple pairs of as and bs in the string. For example, consider the string abba. This
string has two pairs: ab and ba. So, we need to repeat this pairing pattern until the end:
^(a.*b|b.*a)*$Up until now, we have been ignoring the portion of the string between the paired a and b characters with a .*. However,
we also need to ensure that this substring has an equal number of as and bs. For example, consider the string aabb.
This string contains an ab pair within an ab pair. This is a perfect use case for recursion! So, our new regex looks like
this:
^(a(?1)*b|b(?1)*a)*$This regex matches any string with an equal count of as and bs, assuming the string only contains as and bs.
Matching Equal Counts (part 2)
Now, we can extend this regex to match any string with equal counts of as and bs, regardless of what other characters
it contains.
All that we need to do this is to skip characters that are not as or bs. One way we could do this is with an exclusive
set. In regex, the set [^ab] will match any character that is not an a or b. So, we can modify our regex as such:
^([^ab]+|a(?1)*b|b(?1)*a)*$However, eventually, we will want to use this regex to test any arbitrary captured characters, not just a and b.
Unfortunately, we cannot put backreferenced captured strings into a set, so we will need to use a different approach to
match any character except a or b.
The method I came up with to do this is using negative lookaheads. Putting a negative lookahead before a pattern will cause
that pattern to not match if the negative lookahead matches. So, the following pattern will match any character
that is not an a or b:
(?!a|b).We can replace our exclusive set with this negative lookahead:
^(((?!a|b).)+|a(?1)*b|b(?1)*a)*$We now have a regex that matches any string with equal counts of as and bs, while ignoring all other characters!
Extending to Captured Characters
Now, we can extend our regex to match any two characters, not just a and b. Our original algorithm idea was to step
through the string and check if consecutive characters have equal counts. For now, we will not worry about stepping through
the string; we will only check if the first character has the same count as the second character.
To start, we just need to capture the first and second characters:
^(.)(.)However, we run into an issue here. We can’t just append our equal-counts regex after the captures because the captures have already consumed the first two characters of the string. Our equal-counts regex must run on the entire string.
Furthermore, our equal-counts regex must not consume any characters; eventually, we will have to extend this regex to step through the string character-by-character. The only way to iterate through the string is to consume characters one-by-one, so if the equal-counts regex consumed characters, it would disturb the iteration.
The solution I came up with is to first use a positive lookahead to go to the end of the string, then use a negative lookahead to reset the position back to the start of the string. Lookaheads do not consume characters, so this does exactly what we need! This technique looks like this:
(?= .*$ # Goto end of string (?<= ^ # Reset back to beginning of string
# Equal-counts regex: (((?!a|b).)+|a(?1)*b|b(?1)*a)*$ ))Now, we can append this to the regex that captures the first and second characters, and substitute the equal-counts regex’s
a and b with group backreferences:
^(.)(.)(?= .*$ # Goto end of string (?<= ^ # Reset back to beginning of string
# Equal-counts regex: (((?!\1|\2).)+|\1(?3)*\2|\2(?3)*\1)*$ ))Great! We now have a regex that matches any string with equal counts of the first two characters.
Iterating the String
Our original algorithm idea was to iterate through the string and check if consecutive characters have equal counts. I did spend about an hour trying to implement this, and came up with the following regex:
^(?:(.)(?=$|(.)
.*$(?<=^
(?<main_loop> ((?!\1|\2).)+ |\1(?&main_loop)*\2 |\2(?&main_loop)*\1 )*
$)
))*$It did seem to work somewhat well (passed all but a few testcases), but it felt very clunky, inefficient, and used up an unnecessary amount of characters. The main issues with checking if consecutive characters have equal counts were:
- The last character in the string is an edge case that needs special handling, as it has no character after it to compare against. This adds complexity and uses up characters.
- To compare the current character with the character after it, we have to somehow capture the character after the current character without consuming it; I accomplished this by putting a capture in a lookahead, but, this seemed to cause weird, buggy behavior in the regex engine (more on that later).
While working on this regex, I realized that a much more regex-friendly algorithm would be to just capture the first character and compare the counts of every other character against it; rather than comparing the counts of consecutive characters. This algorithm still works due to the aforementioned transitive property of equality.
This new approach eliminates both of the issues with the previous regex:
^# Capture first character; we will test everything against it(.)
(?:# Capture next character to test against the first(.)
(?= # Goto end of string .*$ (?<=
# Test if chars in \1 and \2 have same counts in the string ^ (?<main_loop> ((?!\1|\2).)+ # skip |\1(?&main_loop)*\2 |\2(?&main_loop)*\1 )* $
) )
)*$We’re almost there! This regex passes every test case, except for three. This regex fails to match the following strings:
annanadeededpullupEliminating an Edge Case
Determining the issue with annana and deeded was not too difficult.
Consider the case of annana. The issue here is that as the regex iterates the string, it will eventually try to check if a
has the same count as a. When phrased in English, this sounds like it should pass. However, recall how our equal-counts regex
works: in this case, it will try to pair up every single a with another a. This fails in the case of annana because there
are an odd number of as in the string, so the regex cannot pair up every a with another a.
The issue is identical for deeded, as there is an odd number of ds.
The solution here is simple: we just need to skip checking if a character has the same count as itself. We can do this by adding a special case for this scenario:
^# Capture first character; we will test everything against it(.)
(?:\1| # Skip matching a character against itself
# Capture next character to test against the first(.)
(?= # Goto end of string .*$ (?<=
# Test if chars in \1 and \2 have same counts in the string ^ (?<main_loop> ((?!\1|\2).)+ # skip |\1(?&main_loop)*\2 |\2(?&main_loop)*\1 )* $
) )
)*$Now, our regex passes all test cases but one: pullup.
Fighting with the Regex Engine (part 1)
This is where things start to get weird.
It’s not immediately obvious why pullup fails. Stranger still, if I change the quantifier on the string iteration loop (line 28)
from * to a +?, then suddenly pullup passes, but reappear fails.
What?
That quantifier should have no effect here; the only difference between * and +? is that * is greedy (will try to match as much
as possible) while +? is lazy (will try to match as little as possible). However, we immediately follow up the quantifier with an
end-of-string anchor ($), so whether it is greedy or lazy should not affect the match at all.
This is where I started to suspect a bug in the regex module. Seeing as how the slightest, seemingly inconsequential change to the
regex caused differing results, I decided that if I just randomly messed around with the regex enough, then maybe I could stumble across a
way to make the regex engine not bug out, and pass all test cases.
Indeed, eventually I found that if I use a recursive loop to iterate over the string rather than a * quantifier, then we do
pass all the test cases!
^# Capture first character; we will test everything against it(?<a>.)
(?<big_loop>$|
\g<a>(?&big_loop)| # Skip matching a character against itself
# Capture next character to test against the first(?<b>.)
(?= # Goto end of string .*$ (?<=
# Test if chars in \g<a> and \g<b> have same counts in the string ^ (?<main_loop> ((?!\g<a>|\g<b>).)+ # skip |\g<a>(?&main_loop)*\g<b> |\g<b>(?&main_loop)*\g<a> )* $
) )
(?2))Cutting Characters
We now have a regex that passes all test cases, but unfortunately, when minified, it is 72 characters long (reminder, we need it to be 62 characters or less):
^(.)($|\1(?2)|(.)(?=.*$(?<=^(((?!\1|\3).)+|\1(?4)*\3|\3(?4)*\1)*$))(?2))The first change I came up with to cut characters was in the equal-counts regex: it is unnecessary to put a repeating quantifier on
the skipping-character case, (?!\1|\2)., as all uses of main_loop already have a repeating quantifier. This saves 3 characters, and
looks as follows:
^(?<main_loop> ((?!\1|\2).)+ # skip (?!\1|\2). # skip|\1(?&main_loop)*\2|\2(?&main_loop)*\1)*$Furthermore, we can remove the $ after the equal-counts regex. This is because the equal-counts regex is contained within a lookbehind
that occurs at the end of the string, so the equal-counts regex must necessarily match until the end of the string. This saves another
character:
# Goto end of string.*$ (?<=
# Test if chars in \g<a> and \g<b> have same counts in the string ^ (?<main_loop> ((?!\g<a>|\g<b>).)+ # skip |\g<a>(?&main_loop)*\g<b> |\g<b>(?&main_loop)*\g<a> )* $
))We are now down to 68 characters:
^(.)($|\1(?2)|(.)(?=.*$(?<=^((?!\1|\3).|\1(?4)*\3|\3(?4)*\1)*))(?2))If only we could replace this clunky, hacky recursive string iteration loop with a simple, concise non-recursive loop…
Fighting with the Regex Engine (part 2)
At this point, I just started noodling around with the regex, trying to find a way to use a non-recursive loop to iterate over the string
while having the regex module not bug out.
After some time, I discovered that, while (...)* and (...)+? may not have worked to iterate over the string, ((...)+)? did.
…
This brought the regex down to 63 characters:
^(.)((\1|(.)(?=.*$(?<=^((?!\1|\4).|\1(?5)*\4|\4(?5)*\1)*)))+)?$Unminified, the regex looked as follows:
# Capture first character; we will test everything against it^(?<a>.)
(( \g<a>| # Skip matching a character against itself
# Capture next character to test against the first (?<b>.) (?= # Goto end of string .*$ (?<=
# Test if chars in \g<a> and \g<b> have same counts in the string ^ (?<main_loop> (?!\g<a>|\g<b>). # skip |\g<a>(?&main_loop)*\g<b> |\g<b>(?&main_loop)*\g<a> )*
) ))+)?$After some more noodling around, I discovered that the following changes to the regex cuts it down to exactly 62 characters (minified) and is able to pass all test cases:
# Capture first character; we will test everything against it^(?<a>.)
(( ( \g<a>| # Skip matching a character against itself
# Capture next character to test against the first (?<b>.) (?= # Goto end of string .*$ (?<=
# Test if chars in \g<a> and \g<b> have same counts in the string ^ (?<main_loop> (?!\g<a>|\g<b>). # skip |\g<a>(?&main_loop)*\g<b> |\g<b>(?&main_loop)*\g<a> |\g<a>(?&main_loop)*?\g<b> |\g<b>(?&main_loop)*?\g<a> )*
) ) )+)?$ )*$Minified:
^(.)(\1|(.)(?=.*$(?<=^((?!\1|\3).|\1(?4)*?\3|\3(?4)*?\1)*)))*$I honestly have no clue why this worked.
tjctf{davidebyzero_is_my_hero_6a452cbdc75f}
Solve Scripts
Final regex:
^(.)(\1|(.)(?=.*$(?<=^((?!\1|\3).|\1(?4)*?\3|\3(?4)*?\1)*)))*$Annotated:
# Want to check if the string has equal counts of all the unique characters
# Capture first character; we will test everything against it^(?<a>.)
( \g<a>| # Skip matching a character against itself
# Capture next character to test against the first (?<b>.) (?= # Goto end of string .*$ (?<=
# Test if chars in \g<a> and \g<b> have same counts in the string ^ (?<main_loop> (?!\g<a>|\g<b>). # skip |\g<a>(?&main_loop)*?\g<b> |\g<b>(?&main_loop)*?\g<a> )*
) ))*$import pwn
r = pwn.remote('tjc.tf', 31132)r.sendlineafter(b'> ', br'^a')r.sendlineafter(b'> ', br'^(?=(.|(.)(?1)\2)$).(.)(.)(.).\3.(.).\5\4\6.{13}$')r.sendlineafter(b'> ', br'^($|[03](?1)|[14]([03]([03](?2)|[14](?3)|2(?1))|[14](?1)|2(?2))|2(?3))')r.sendlineafter(b'> ', br'^(?<s0>$|0(?&s0)|1(?<s1>0(?<s2>0(?<s4>0(?&s1)|1(?&s2))|1(?<s5>0(?&s3)|1(?&s4)))|1(?<s3>0(?<s6>0(?&s5)|1(?&s6))|1(?&s0))))')r.sendlineafter(b'> ', br'^(.)(\1|(.)(?=.*$(?<=^((?!\1|\3).|\1(?4)*?\3|\3(?4)*?\1)*)))*$')r.interactive()So… what was up with the regex engine?
After the CTF, the challenge author suggested that the strange regex engine behavior I was encountering likely had to do with the
atomic behavior of lookarounds (it probably wasn’t a bug):
